Deduplikacja 
Deduplikacja to proces eliminacji z bazy danych rekordów równoważnych, jednak niekoniecznie identycznych.
Stosowana jest do łączenia dwóch niezależnych zbiorów danych w celu uzyskania zintegrowanej bazy bez powtarzających się informacji. Innym zastosowaniem deduplikacji jest pomijanie w bazie rekordów, które powielają informacje zawarte już w innych rekordach. Możemy jednak, usuwając powtarzające się rekordy, zachować jednocześnie dane, które wcześniej były rozproszone. Proces deduplikacji składa się z kilku podstawowych faz:
- wyboru kryteriów i łączenia w grupy rekordów potencjalnie powielających się,
- wyboru rekordów nadmiarowych do usunięcia,
- ustalenia grup danych, które mogą być przenoszone pomiędzy rekordami
równoważnymi,
- wzbogacenia rekordów pozostających w bazie, informacjami z rekordów wybranych
do usunięcia,
- usunięcia rekordów zbędnych.
Optymalne wyniki deduplikacji uzyskuje się, łącząc ten proces z czyszczeniem baz
danych. Korzyści:
- obniżenie kosztów poprzez jednokrotną obsługę każdej z informacji (np. tylko
jeden kontakt
z klientem, jeden wykonany telefon, jeden wysłany katalog),
- podwyższenie skuteczności poprzez wzbogacenie posiadanych danych,
- zwiększenie precyzji raportów (lepsza identyfikacja, jednokrotne zliczanie).
Przykłady / praktyka:

Grupy rekordów potencjalnie równoważnych dobierane wg zasady: identyczna miejscowość, identyczna nazwa firm.
Zaznaczony adres stanowi zestaw pól obsługiwanych razem podczas przenoszenia danych miedzy rekordami. Podczas sklejania danych uwzględniane są wartości pól z całego zestawu.
Zaznaczone zostały rekordy wybrane do usunięcia.
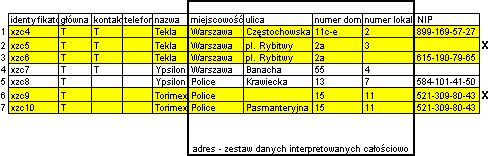
Obraz bazy po dokonanej deduplikacji:

|

